Automatic detection of recursive loops with AWS Lambda
Introduction
You probably saw a lot of horror stories involving a Lambda function going crazy and racking up a giant AWS bill. When I was just starting out, I remember being afraid to make such a costly mistake myself. Luckily, looks like AWS wants to spare its users a few heart attacks as one of the latest releases brings us a new feature, which is automatic detection and stop of recursive loops involving Lambda functions. Let's dive in!
What are we going to do
According to docs, loop detection works only if the loop consists of AWS Lambda, AWS SQS or AWS SNS. In this blog post we'll build a simple service that will have such a recursive loop and we will test how AWS deals with such invocations.
Prerequisites
We will be using Serverless Framework to build simple application to test out this feature. As our language of choice, we will be using Python 3.9, so please make sure to install it ahead of time if you want to experiment yourself too.
Recursive loop - first attempt
Let's start simple. We will deploy a service with an AWS Lambda function that consumes message from SQS queue and automatically republishes it to the same queue. The diagram of our service will look more or less like this:
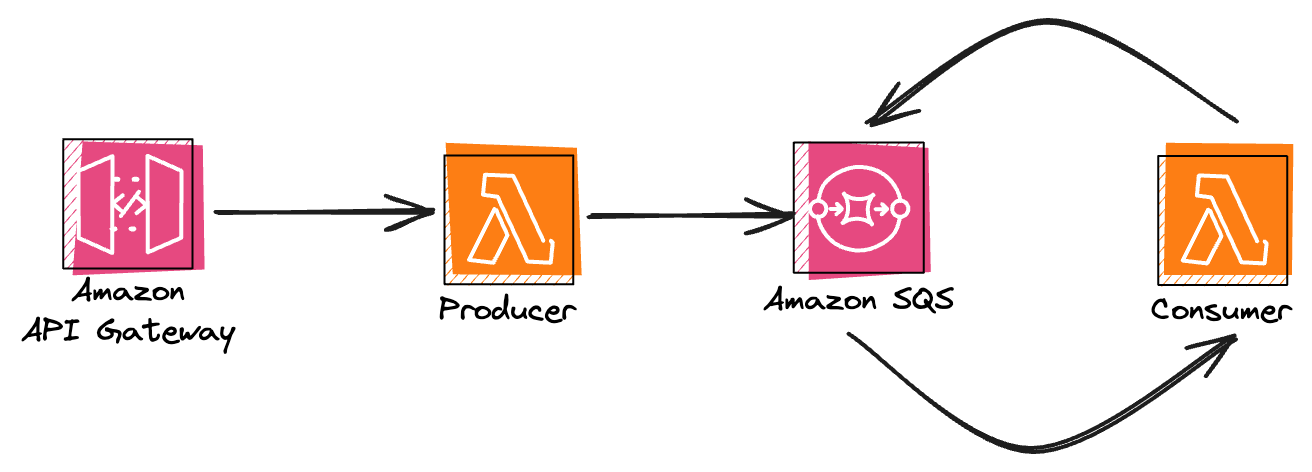
Service setup
As we will be using Serverless Framework in this example, let's bootstrap our project from a predefined template with the following command:
sls create --template aws-python --path serverless-recursive-loopsIt will create a project with the following structure:
serverless-recursive-loops
├── README.md
├── handler.py
└── serverless.ymlLet's clean up our serverless.yml so it will deploy all necessary resources:
service: aws-python-sqs-worker-loop
frameworkVersion: '3'
provider:
name: aws
runtime: python3.9
deploymentMethod: direct
stage: dev
iam:
role:
statements:
- Effect: Allow
Action:
- sqs:SendMessage
Resource:
- Fn::GetAtt: [ WorkerQueue, Arn ]
functions:
producer:
handler: handler.producer
events:
- http:
method: post
path: produce
environment:
QUEUE_URL:
Ref: WorkerQueue
consumer:
handler: handler.wild_consumer
environment:
QUEUE_URL:
Ref: WorkerQueue
events:
- sqs:
batchSize: 1
arn:
Fn::GetAtt:
- WorkerQueue
- Arn
resources:
Resources:
WorkerQueue:
Type: AWS::SQS::Queue
Properties:
QueueName: workerQueue-loop-${self:provider.stage}
Additionally, let's modify our handler.py to include producer and wild_consumer functions for our Lambda functions:
import json
import logging
import os
import time
import boto3
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
QUEUE_URL = os.getenv('QUEUE_URL')
SQS = boto3.client('sqs')
def producer(event, context):
status_code = 200
message = ''
if not event.get('body'):
return {'statusCode': 400, 'body': json.dumps({'message': 'No body was found'})}
try:
message_attrs = {
'AttributeName': {'StringValue': 'AttributeValue', 'DataType': 'String'}
}
SQS.send_message(
QueueUrl=QUEUE_URL,
MessageBody=event['body'],
MessageAttributes=message_attrs,
)
message = 'Message accepted!'
except Exception as e:
logger.exception('Sending message to SQS queue failed!')
message = str(e)
status_code = 500
return {'statusCode': status_code, 'body': json.dumps({'message': message})}
def wild_consumer(event, context):
for record in event['Records']:
message_attrs = {
'AttributeName': {'StringValue': 'AttributeValue', 'DataType': 'String'}
}
SQS.send_message(
QueueUrl=QUEUE_URL,
MessageBody=record['body'],
MessageAttributes=message_attrs,
)
Okay, now we're ready to deploy our service:
sls deployAfter the deployment is finished, you should see the output similar to:
Deploying aws-python-sqs-worker-loop to stage dev (us-east-1)
✔ Service deployed to stack aws-python-sqs-worker-loop-dev (36s)
endpoint: POST - https://xxxxxxxx.execute-api.us-east-1.amazonaws.com/dev/produce
functions:
producer: aws-python-sqs-worker-loop-dev-producer (1.2 kB)
consumer: aws-python-sqs-worker-loop-dev-consumer (1.2 kB)Let's grab the url and try to call it, which will publish first message to SQS queue, starting our loop:
curl --request POST https://qywqabxxb7.execute-api.us-east-1.amazonaws.com/dev/produce --header 'Content-Type: application/json' --data-raw '{"name": "Oops!"}'Now let's observe what happens with our function. Will it be stopped or are we making AWS richer, one Lambda invocation at a time?
Observations
After observing logs, I noticed that the invocations are stopped very quickly. Documentation explains that after 16 invocations in the same loop the Lambda function will be stopped and that's exactly what I observed. Unfortunately, the notifications around loop detection are not the quickest. The most reliable way to detect is to observe Recursive invocations dropped metric, but from my experience it can by a bit delayed, in tested cases it took more than 5 minutes to show new dropped invocations. Below you can see an example of how the metric looks like in the dashboard.
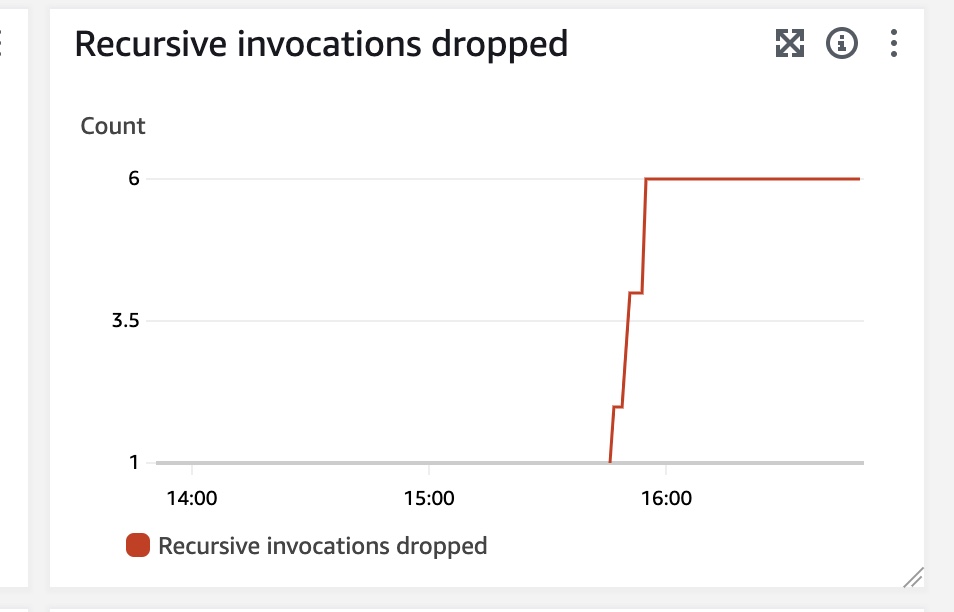
Additionally, you can also observe "Lambda runaway termination notification" events in AWS Health Dashboard. You will also receive an email about stopping Lambda functions involved in recursive invocations. In all tested cases the event in AWS Health and email became visible after roughly 3 hours after the termination happened. Probably the best way to detect such invocations quicker would be setting up a custom CloudWatch Alarm on Recursive Invocations dropped metric.
Recursive loop - second attempt
Okay, the first example was easy - single Lambda function that was publishing over and over to the same SQS queue. Let's make it a little bit more complex by introducing a second Lambda function and second SQS queue. The diagram of our service will look more or less like this:
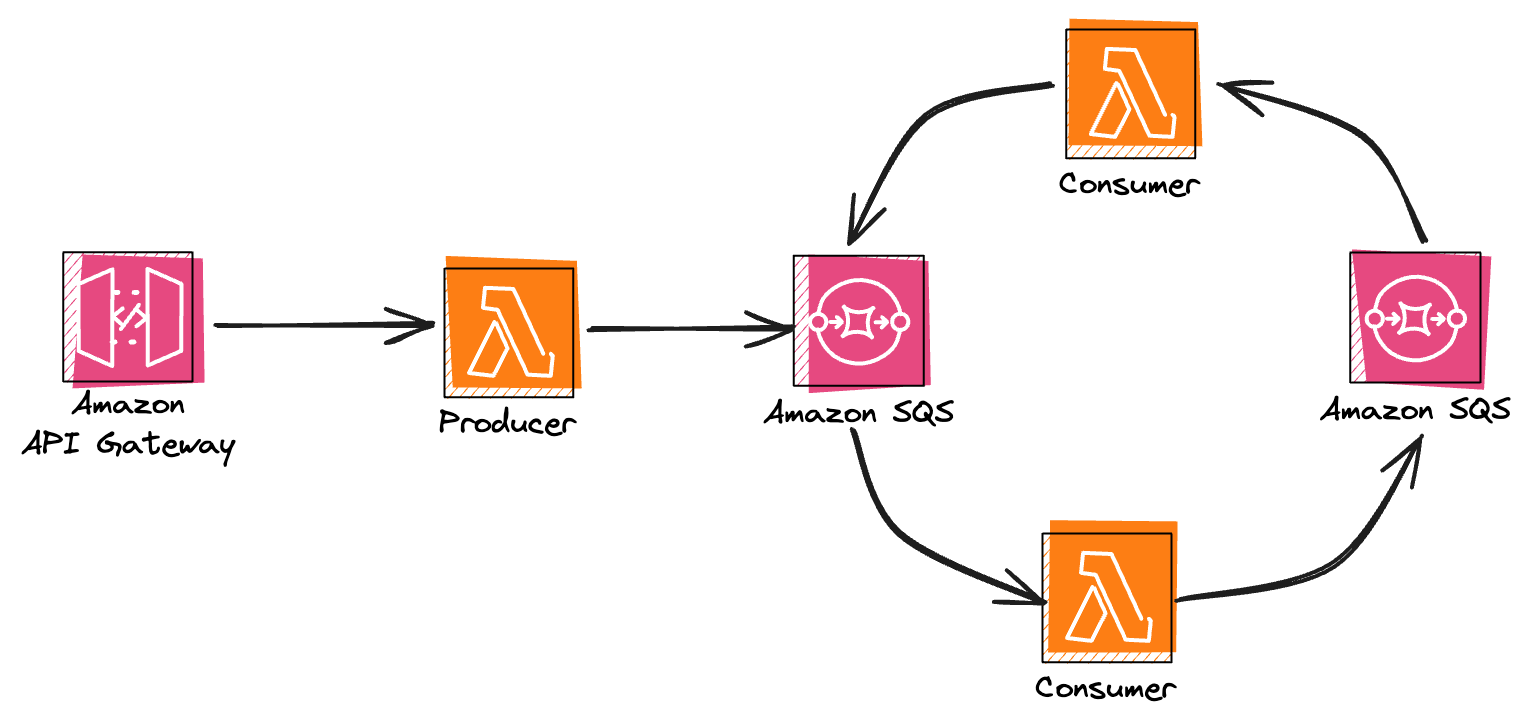
Service setup
We need to tweak our serverless.yml to provision an additional function and an extra SQS queue:
service: aws-python-sqs-worker-loop
frameworkVersion: '3'
provider:
name: aws
runtime: python3.9
deploymentMethod: direct
stage: dev
iam:
role:
statements:
- Effect: Allow
Action:
- sqs:SendMessage
Resource:
- Fn::GetAtt: [ WorkerQueue, Arn ]
- Effect: Allow
Action:
- sqs:SendMessage
Resource:
- Fn::GetAtt: [ OtherWorkerQueue, Arn ]
functions:
producer:
handler: handler.producer
events:
- http:
method: post
path: produce
environment:
QUEUE_URL:
Ref: WorkerQueue
consumer:
handler: handler.wild_consumer
environment:
QUEUE_URL:
Ref: WorkerQueue
events:
- sqs:
batchSize: 1
arn:
Fn::GetAtt:
- OtherWorkerQueue
- Arn
otherConsumer:
handler: handler.wild_consumer
environment:
QUEUE_URL:
Ref: OtherWorkerQueue
events:
- sqs:
batchSize: 1
arn:
Fn::GetAtt:
- WorkerQueue
- Arn
resources:
Resources:
WorkerQueue:
Type: AWS::SQS::Queue
Properties:
QueueName: workerQueue-loop-${self:provider.stage}
OtherWorkerQueue:
Type: AWS::SQS::Queue
Properties:
QueueName: otherWorkerQueue-loop-${self:provider.stage}Okay, now we're ready to deploy our service again:
sls deployAfter the deployment is finished, lets try to start the loop again:
curl --request POST https://qywqabxxb7.execute-api.us-east-1.amazonaws.com/dev/produce --header 'Content-Type: application/json' --data-raw '{"name": "Oops!"}'Are we going to trick loop detector or is it going to stop our wild consumers?
Observations
In this case, the reaction is also very quick. The first of the consumers stopped after 16 iterations again, effectivelly stopping the whole execution loop. Once again, AWS prevented us from racking up a huge bill.
Few takeaways and gotchas
As we can see based on the tested scenarios above, automatic loop detection can be very useful and can help us prevent problematic infinite (or just very big) invocation loops. Unfortunately, it is not ideal, as it only supports a limited set of AWS services and if the loop involves services like S3 or DynamoDB, it won't protect you anymore. In general it works nicely, but I have to say it would be great to get notifications much quicker than after 3 hours. Of course, you can still set up alarms on RecursiveInvocationsDropped metric, but that adds an extra step for this out-of-the-box feature and you might not think of setting it up before you ran into your first recursive loop.
Supported runtimes
In our examples we were using Python, which is one of the runtimes that support loop detection. But what if you're not using Python? As long as you're using one of the default runtimes (with the exception of go1.x) along with corresponding AWS SDK in required version, you'll get the loop detection feature. Unfortunately, if you're using a custom runtime, the feature is not available and I did not find an option to include it in your provided runtime.
Supported services
To recap again, the only supported services are AWS Lambda, AWS SQS, and AWS SNS. If the loop would involve another service such as Amazon S3 or Amazon DynamoDB, then the loop detection will fail. Please keep that in mind when writing your Lambda functions integrating with these services that have a potential to be recursive under certain circumstantes, as the loop detection won't save you there.
What if I don't want my loops to break?
Okay, the protective measures are great, but what if the looping behavior is intendted in your workflow and e.g. you know that your loops will always have a bounded number of iterations? Out of a sudden you might observe your workflows breaking due to loop detection mechanism. Fortunately, if you know what you're doing (!), you can contact AWS Support to disable this behavior.
Summary
In this short article we had a chance to test out one of the recent features added to AWS Lambda, which is recursive loop detection. We explored how it works, in what situations it can helps us, and in which situations it won't be effective at all. It's great to have more safety nets built in, but since this mechanism support only a limited amount of services, you still need to stay vigilant when writing Lambda functions that can be recursive. Maybe you should reconsider your implementation to avoid recursive patterns in the first place? Thanks for reading!